Expression
Press down on the pad below. An AI will improvise a piano performance while you control the number of notes played and their loudness.
This AI is a neural network trained on approximately 1400 performances from a piano competition. The training data is captured using Yamaha Disklavier pianos that record each key pressed and the intensity of each press (this is called “velocity”). The AI was designed to learn what notes to play, but also how to play them with the expressive timing and dynamics of a human performer. The AI outputs notes, which are fed into a sampler that triggers recordings of a real piano to create the audio you hear.
Up ahead, we’ll
Playing with feeling
When we talk, we add meaning, emotion, and subtext by altering our words’ pitch, intensity, and timing. We can say “Happy new year” with happiness, sadness, or sarcasm without changing a single letter. An old-timey robot would say one word after another in a monotonous way and sound lifeless and mechanical.
Musicians also play their notes with expressiveness to provide feeling, meaning, and emotion or to provoke a physical response in the audience. Some of the elements that come into play:
- Dynamics: How loud each note is played. Individual notes can be accented, or whole phrases can be played louder or softer. Also, sometimes the loudness increases or diminishes gradually.
- Articulation: How notes are sounded, particularly how they begin and end. They can be briefly tapped, span their entire duration, or slide one into another.
- Each instrument provides unique ways to articulate. For example, an acoustic guitar sounds different whether you strum up or down. The sound of brass instruments can be articulated by blocking the air with the tongue in many different ways.
- Tempo: A musician or band might speed up or slow down the tempo slightly during a portion of a song for expressive reasons.
- Groove: Sometimes, to get the right “feel,” a musician will play slightly behind or slightly ahead of the beat or with tiny rhythmic variations.
Sheet music includes markings to suggest some of these expressive adjustments. They’re also the mechanisms through which a conductor or musician can interpret a piece in their personal style. They can also be part of the identifiable “sound” or “feel” of a genre in a particular city or region, developed collectively by local musicians playing together through many years.
We can train an AI to reproduce any of these elements by:
- training it with data from actual human performances (instead of written music)
- encoding the notes in a way that can express these subtle variations in loudness, timing, timbre, pitch, etc.
Expressive electronic music

Electronic instruments can be extremely expressive. The early examples presented in the “Artist” chapter illustrate this. Clara Rockmore developed a way of playing the theremin using specific hand positions and precise finger gestures to control the tone. She said that even swaying your head, or moving your feet could affect the result. Synthesizers, like the Moog played by Wendy Carlos, offer multiple parameters that can be modulated expressively even while playing a single note on the keyboard. Daphne Oram’s Oramic Synthesis had all the expressive potential of the brush strokes fed through the film tapes to shape its sound. She stated her goal: “Every nuance, every subtlety of phrasing, every tone gradation or pitch inflection must be possible just by a change in the written form.”
Some of the drum machines from the “Rhythm” chapter represent “quantization,” which is placing the notes on a grid perfectly aligned with the beat, removing both accidental imprecisions and expressiveness. Sometimes quantization is an artistic choice and a way to transmit a particular feeling. Still, in early drum machines, it was also a consequence of early digital technology not being able to capture exact timing or to store it with precision in the limited memory available.
Modern digital music software is usually based on a grid defined by precisely timed beats. Musicians can use a “click track” (a steady metronome sounding on their headphones) to align their playing to this grid. This enables producers to combine separate recordings, layer, repeat, loop, and move them around the grid like pieces in a mosaic. They can also break from the grid for a more organic, expressive, elastic tempo, but at the cost of the ability to produce music by rearranging and layering parts freely.
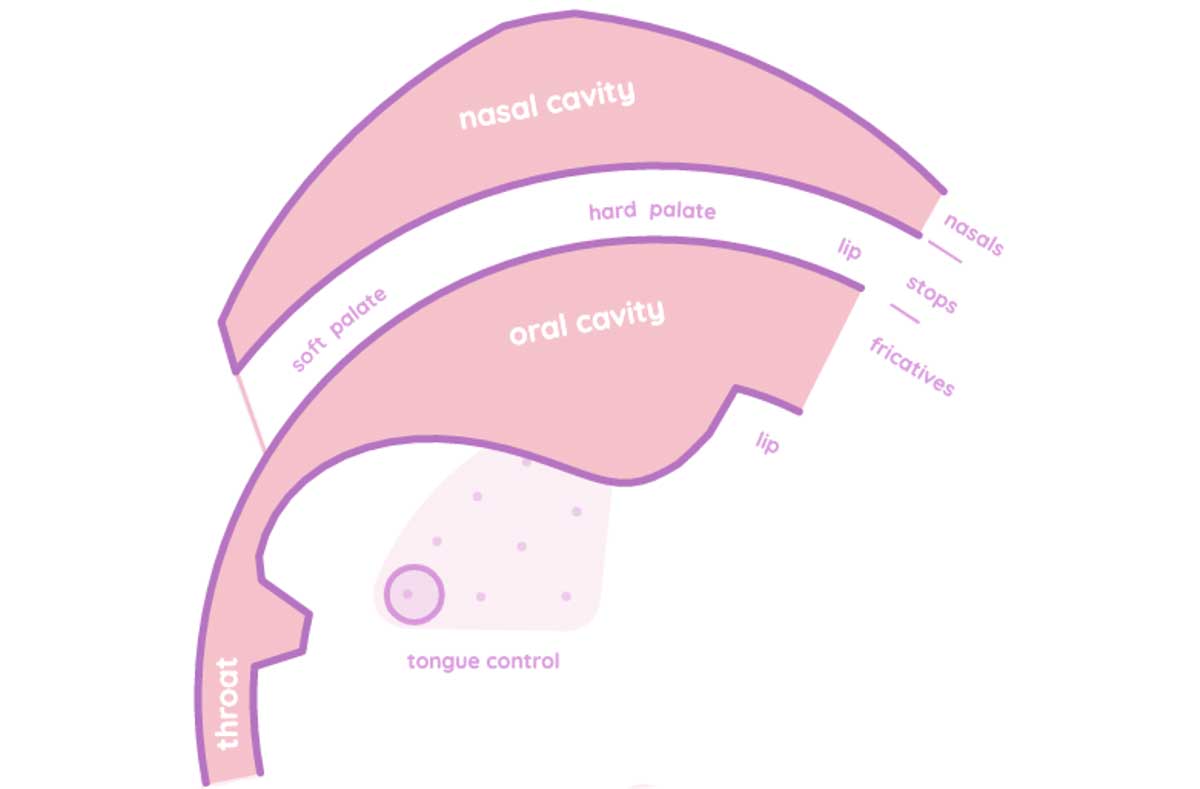
Digital music software and hardware can offer seemingly endless options to precisely control the timing and articulation of sound. However, most expression in music is generated intuitively by the performer, without conscious decisions and maybe even without intellectual understanding. A good and extremely fun example of this disconnection is Pink Trombone by Neil Thapen, a program that lets you synthesize human speech by individually controlling the different parts of the vocal apparatus. Electronic instrument design involves developing modes of input that can capture a rich palette of articulation and nuance through expressive gestures made intuitively.
How does our AI work?
In other chapters, you can find an AI that creates drum machine patterns and an AI that creates basslines. These use neural networks that output notes on a grid that subdivides time into fixed steps of around 150 milliseconds (at a tempo of 100bps). Notes can only start or end at the beginning of a step and always have the same loudness. These neural networks use a simplified representation of music that cannot capture or reproduce human expression as we’ve seen it.
However, the neural network in this chapter can indicate the start and end of notes with a resolution of 10ms. Each note can have 32 different levels of loudness (velocity).
You can think of this as low-resolution black and white versus high-resolution grayscale photos. This extra level of detail comes at a cost: the neural network will require more training time and more training data to reach an acceptable level of quality.
Beyond their velocity and duration, notes can have one of 128 pitches. Since the network was trained on piano performances, this is an adequate representation of articulation. To encode the expressive playing of a guitar, violin, or saxophone, we would need a much larger amount of information, since there are many more factors that can affect the sound of a note. Getting training data would also be harder, maybe involving several cameras and body tracking software or instruments filled with sensors.
According to its authors, what makes this AI interesting is the data its been trained on and the way it represents notes allowing for expression. The neural network is not novel in other ways. It can learn dynamics and expressive timing because, just like the notes, they don’t happen randomly. Expression also follows an underlying structure that can be learned and reproduced.
Food for thought
Neural Networks can learn to understand rich and nuanced human expression without us needing to enumerate (or even understand) the “rules” that guide it. They can recognize handwriting, the mood behind a piece of text, the emotion conveyed by a face, etc.
Thus, we could think of an AI-powered instrument that allows us to control musical expression through dance, acting, painting, cooking, gardening, or any other expressive physical (or even mental?) action. What would be a good match? What new possibilities would it create? How far can we stretch the concept of playing music?
External links
- See the source code in our Github repository.
- Discover the “Con Espressione” exhibit.
Credits
Interactive content adapted from the Performance RNN AI by Ian Simon and Sageev Oore (Google Magenta).
Copyright and license information in our GitHub repository.
References
- Ian Simon, Sageev Oore. “Performance RNN: Generating Music with Expressive Timing and Dynamics.” Magenta. Google. 2017-06-29. Retrieved on 2022-12-10.
- “The Art of Articulations”. 12tone. YouTube. 2017-11-10. Retrieved on 2022-12-12.
- Wikipedia contributors. “Groove (music).” Wikipedia, The Free Encyclopedia. 2022-11-30. Retrieved on 2022-12-12.
- Wikipedia contributors. “Expressive timing.” Wikipedia, The Free Encyclopedia. 2021-11-22. Retrieved on 2022-12-12.
- Wikipedia contributors. “Articulation (music).” Wikipedia, The Free Encyclopedia. 2022-11-9. Retrieved on 2022-12-12.
- Wikipedia contributors. “Dynamics (music).” Wikipedia, The Free Encyclopedia. 2022-11-19. Retrieved on 2022-12-12.
- Albert Glinsky. “Theremin : ether music and espionage”. Urbana : University of Illinois Press. 2000.
Text is available under the Creative Commons Attribution License . Copyright © 2022 IMAGINARY gGmbH.