Ausdruck
Drücke auf das Feld hier unten. Eine KI improvisiert ein Klavierstück, während du die Anzahl der gespielten Noten und deren Lautstärke bestimmst.
Bei dieser KI handelt es sich um ein neuronales Netz, das anhand von rund 1400 Darbietungen eines Klavierwettbewerbs trainiert wurde. Die Trainingsdaten wurden mit Hilfe eines Yamaha-Disklaviers erfasst, das jeden Tastendruck und die Intensität jedes Anschlags aufzeichnet (dies wird als „Anschlagstärke“ bezeichnet). Die KI wurde so konzipiert, dass sie nicht nur lernt, die richtigen Noten zu spielen, sondern auch wie sie diese mit dem ausdrucksstarken Timing und der Dynamik von menschlichen Interpret*innen spielen kann. Die KI gibt Noten aus, die in einen Sampler eingespeist werden. Dieser spielt die Aufnahmen eines echten Klaviers ab und erzeugt dann die Töne, die du hörst.
In diesem Kapitel werden wir
Spielen mit Gefühl
Wenn wir sprechen, können wir Bedeutung, Emotionen und unterschwellige Botschaften in unsere Aussagen hineinlegen, indem wir die Tonlage, die Intensität und das Timing unserer Worte verändern. Wir können zum Beispiel „Frohes neues Jahr“ mit Freude, Traurigkeit oder Sarkasmus sagen, ohne dabei die Buchstaben zu verändern. Ein Blechdosenroboter aus alten Zeiten würde dagegen ein Wort nach dem anderen auf monotone Weise sagen und leblos und mechanisch klingen.
Auch Musiker*innen möchten Gefühle, Bedeutungen und Emotionen vermitteln oder Reaktionen beim Publikum hervorrufen und spielen deshalb ihre Noten ausdrucksstark. Einige der Mittel, die sie dabei verwenden, sind hier angeführt:
- Dynamik gibt an, wie laut jede Note gespielt wird. Einzelne Noten können akzentuiert werden, oder ganze Phrasen können lauter oder leiser gespielt werden. Manchmal nimmt die Lautstärke auch allmählich zu oder ab.
- Artikulation fasst zusammen, wie die Noten erklingen, insbesondere wie sie beginnen und enden. Sie können kurz angetippt werden, sich über ihre gesamte Dauer erstrecken oder ineinander übergehen.
- Jedes Instrument bietet einzigartige Möglichkeiten, sich zu artikulieren. Eine Akustikgitarre zum Beispiel klingt anders, wenn man sie von oben oder unten anschlägt. Der Klang von Blechblasinstrumenten kann durch das Blockieren der Luft mit der Zunge auf viele verschiedene Arten artikuliert werden.
- Tempo: Ein*e Musiker*in oder eine Band kann das Tempo während eines Teils eines Liedes leicht beschleunigen oder verlangsamen, um den Ausdruck zu verändern.
- Groove: Um das richtige „Gefühl“ zu bekommen, spielen Musiker*innen manchmal leicht hinter oder vor dem Takt oder mit geringfügigen rhythmischen Abweichungen.
Notenblätter enthalten oft Markierungen, die diese Ausdrucksmöglichkeiten an bestimmten Stellen vorschlagen. Diese Mittel werden auch von Dirigent*innen oder Musiker*innen genutzt, um ein Musikstück in ihrem persönlichen Stil zu interpretieren. Darüber hinaus können diese Mittel auch Teil des charakteristischen „Klangs“ oder „Gefühls“ eines Genres sein oder typisch für eine bestimmte Stadt oder Region, in der lokale Musiker*innen über viele Jahre hinweg gemeinsam einen spezifischen Sound entwickelt haben.
Wir können eine KI darauf trainieren, jedes dieser Ausdrucksmittel zu reproduzieren, indem wir
- sie mit Daten von tatsächlichen menschlichen Darbietungen trainieren (anstelle einer niedergeschriebenen Partitur).
- die Noten so kodieren, dass sie diese subtilen Variationen in Lautstärke, Timing, Klangfarbe, Tonhöhe usw. wiedergeben können.
Ausdrucksstarke elektronische Musik

Elektronische Instrumente können sehr ausdrucksstark sein. Die Beispiele aus früheren Zeiten, die wir im Kapitel über Kunstfertigkeit gesehen haben, veranschaulichen dies. Clara Rockmore entwickelte eine Spielweise für das Theremin, bei der bestimmte Handpositionen und präzise Fingergesten zur Steuerung des Tons eingesetzt wurden. Sie sagte, dass sogar das Wiegen des Kopfes oder das Bewegen der Füße das Ergebnis beeinflussen kann. Synthesizer, wie der von Wendy Carlos gespielte Moog, bieten mehrere Parameter, die ausdrucksstark moduliert werden können, während man nur eine einzige Note auf der Tastatur spielt. Daphne Orams Oramics-Technik verfügte über das gesamte Ausdruckspotenzial der Pinselstriche, die durch die Filmbänder geführt wurden, um den Klang zu formen. Daphne Oram formulierte ihr Ziel folgendermaßen: „Jede Nuance, jede Subtilität der Phrasierung, jede Tonabstufung oder Tonhöhenverbiegung muss allein durch eine Veränderung der geschriebenen Form möglich sein.“
Einige der Drumcomputer aus dem Kapitel „Rhythmus“ erzeugen eine „Quantisierung“. Dabei werden Noten auf einem Raster platziert, das perfekt auf den Beat abgestimmt ist. Sowohl zufällige Ungenauigkeiten als auch die Ausdruckskraft werden dadurch entfernt. Manchmal ist die Quantisierung eine künstlerische Entscheidung und eine Möglichkeit, ein bestimmtes Gefühl zu vermitteln. Bei den ersten Drumcomputern war sie jedoch auch eine Folge der Tatsache, dass die frühe Digitaltechnik nicht in der Lage war, ein exaktes Timing zu erfassen oder es in dem begrenzten verfügbaren Speicher präzise zu sichern.
Moderne digitale Musiksoftware basiert in der Regel auf einem Raster, das durch genau getaktete Beats definiert ist. Musiker*innen können einen „Clicktrack“ (ein gleichmäßiges Metronom, das über ihre Kopfhörer abgespielt wird) verwenden, um ihr Spiel an diesem Raster auszurichten. Auf diese Weise können die Produzent*innen einzelne Aufnahmen kombinieren, überlagern, wiederholen, loopen und wie Mosaiksteine auf dem Raster verschieben. Wenn sie ein organischeres, ausdrucksstärkeres und elastischeres Tempo erreichen wollen, können sie auch aus dem Raster ausbrechen. Das geht allerdings auf Kosten der kreativen Freiheit, Musik zu produzieren, bei der einzelne Songelemente frei angeordnet oder überlagert werden.
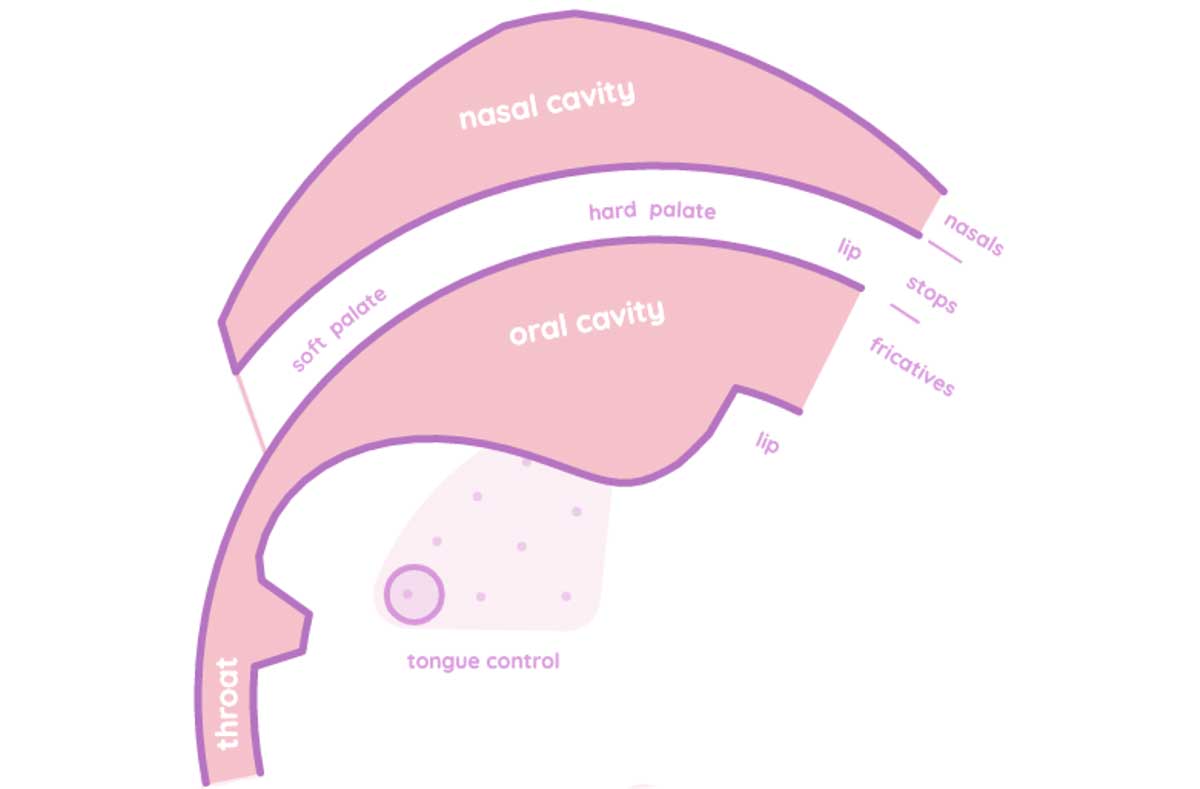
Digitale Musiksoftware und -hardware bietet scheinbar unendliche Möglichkeiten, das Timing und die Artikulation von Klängen präzise zu steuern. Meistens wird der Ausdruck in der Musik jedoch intuitiv von den Interpret*innen erzeugt, ohne bewusste oder rationale Entscheidungen.Ein gutes und sehr unterhaltsames Beispiel für diese Entkopplung ist Pink Trombone von Neil Thapen. Mit diesem Programm kann man menschliche Sprache synthetisieren und die verschiedenen Teile des Stimmapparats individuell steuern. Bei der Entwicklung elektronischer Instrumente geht es ebenfalls darum, Eingabemethoden zu entwickeln, mit denen man eine große Bandbreite an Artikulationen und Nuancen durch intuitiv ausgeführte, ausdrucksstarke Bewegungen erzeugen kann.
Wie funktioniert die KI?
In anderen Kapiteln findest du eine KI, die Drumcomputer-Patterns erstellt, und eine KI, die Basslinien erzeugt. Beide verwenden neuronale Netze, die Töne auf einem Raster ausgeben. Dort ist die Zeit in feste Abschnitte von etwa 150 Millisekunden unterteilt (bei einem Tempo von 100bps). Töne können nur am Anfang eines Abschnitts beginnen oder enden und haben immer die gleiche Lautstärke. Diese neuronalen Netze verwenden eine vereinfachte Darstellung von Musik, die den menschlichen Ausdruck, wie wir ihn kennen, nicht erfassen oder reproduzieren können.
Das neuronale Netz in diesem Kapitel kann jedoch den Anfang und das Ende von Tönen mit einer Genauigkeit von 10 ms angeben. Jede Note kann 32 verschiedene Lautstärkestufen (Anschlagsstärken) haben.
Dies ist in etwa so, als würde man Schwarz-Weiß-Fotos mit niedriger Auflösung mit hochauflösenden Graustufenfotos vergleichen. Diese zusätzliche Detailgenauigkeit hat ihren Preis: Das neuronale Netz benötigt mehr Trainingszeit und mehr Trainingsdaten, um dieses höhere Maß an Qualität zu erreichen.
Neben der Anschlagstärke und der Dauer können die Töne eine von 128 Tonhöhen haben. Da das neuronale Netz mit gespielten Klavierstücken trainiert wurde, ist dies eine angemessene Darstellung der Artikulation. Um das ausdrucksstarke Spiel einer Gitarre, Geige oder eines Saxophons zu kodieren, bräuchten wir eine viel größere Menge an Informationen, da es viel mehr Faktoren gibt, die dort den Klang eines Tons beeinflussen können. Auch die Erfassung von Trainingsdaten wäre schwieriger. Dazu wären wahrscheinlich mehrere Kameras, Motion-Tracking-Software oder mit Sensoren ausgestattete Instrumente erforderlich.
Den Entwicklern zufolge ist das Besondere an dieser KI zum einen der Datensatz, mit dem sie trainiert wurde. Zum anderen ist es die Art, wie die KI Noten darstellt, um ein Spiel mit Ausdruck zu ermöglichen. Das neuronale Netz ist sonst nicht neu oder anders. Es kann Dynamik und ausdrucksstarkes Timing erlernen, weil diese, genau wie die Töne, nicht zufällig auftreten. Auch der Ausdruck folgt einer zugrunde liegenden Struktur, die gelernt und reproduziert werden kann.
Einige Punkte zum Nachdenken
Neuronale Netze können lernen, reichhaltige und nuancierte menschliche Ausdrucksformen zu verstehen, ohne dass wir die „Regeln“, nach denen sie funktionieren, aufzählen (oder gar verstehen) müssen. Sie können Handschriften, die Stimmung hinter einem Text, die Emotionen, die ein Gesicht vermitteln, usw. erkennen.
Wir könnten uns also ein KI-gesteuertes Instrument vorstellen, das es uns ermöglicht, den musikalischen Ausdruck durch Tanzen, Schauspielern, Malen, Kochen, Gartenarbeit oder irgendeine andere ausdrucksstarke körperliche (oder sogar geistige?) Handlung zu steuern. Was wäre eine gute Wahl? Welche neuen Möglichkeiten würden sich daraus ergeben? Wie weit können wir das Konzept des Musizierens erweitern?
Externe Links
- Sieh dir den Quellcode in unserem Github-Repository an.
- Entdecke das Exponat „Con Espressione“.
Referenzen
Der interaktive Inhalt wurde von der Performance RNN AI von Ian Simon und Sageev Oore (Google Magenta) übernommen.
Copyright- und Lizenzinformationen sind in unserem GitHub-Repository.
Quellenangaben
- Ian Simon, Sageev Oore. „Performance RNN: Generating Music with Expressive Timing and Dynamics.“ Magenta. Google. 2017-06-29. Abgerufen am 2022-12-10.
- „The Art of Articulations.“. 12tone. YouTube. 2017-11-10. Abgerufen am 2022-12-12.
- Wikipedia contributors. „Groove (music).“ Wikipedia, The Free Encyclopedia. 2022-11-30. Abgerufen am 2022-12-12.
- Wikipedia contributors. „Expressive timing.“ Wikipedia, The Free Encyclopedia. 2021-11-22. Abgerufen am 2022-12-12.
- Wikipedia contributors. „Articulation (music).“ Wikipedia, The Free Encyclopedia. 2022-11-9. Abgerufen am 2022-12-12.
- Wikipedia contributors. „Dynamics (music).“ Wikipedia, The Free Encyclopedia. 2022-11-19. Abgerufen am 2022-12-12.
- Albert Glinsky. „Theremin : ether music and espionage.“ Urbana : University of Illinois Press. 2000.
Text is available under the Creative Commons Attribution License . Copyright © 2022 IMAGINARY gGmbH.